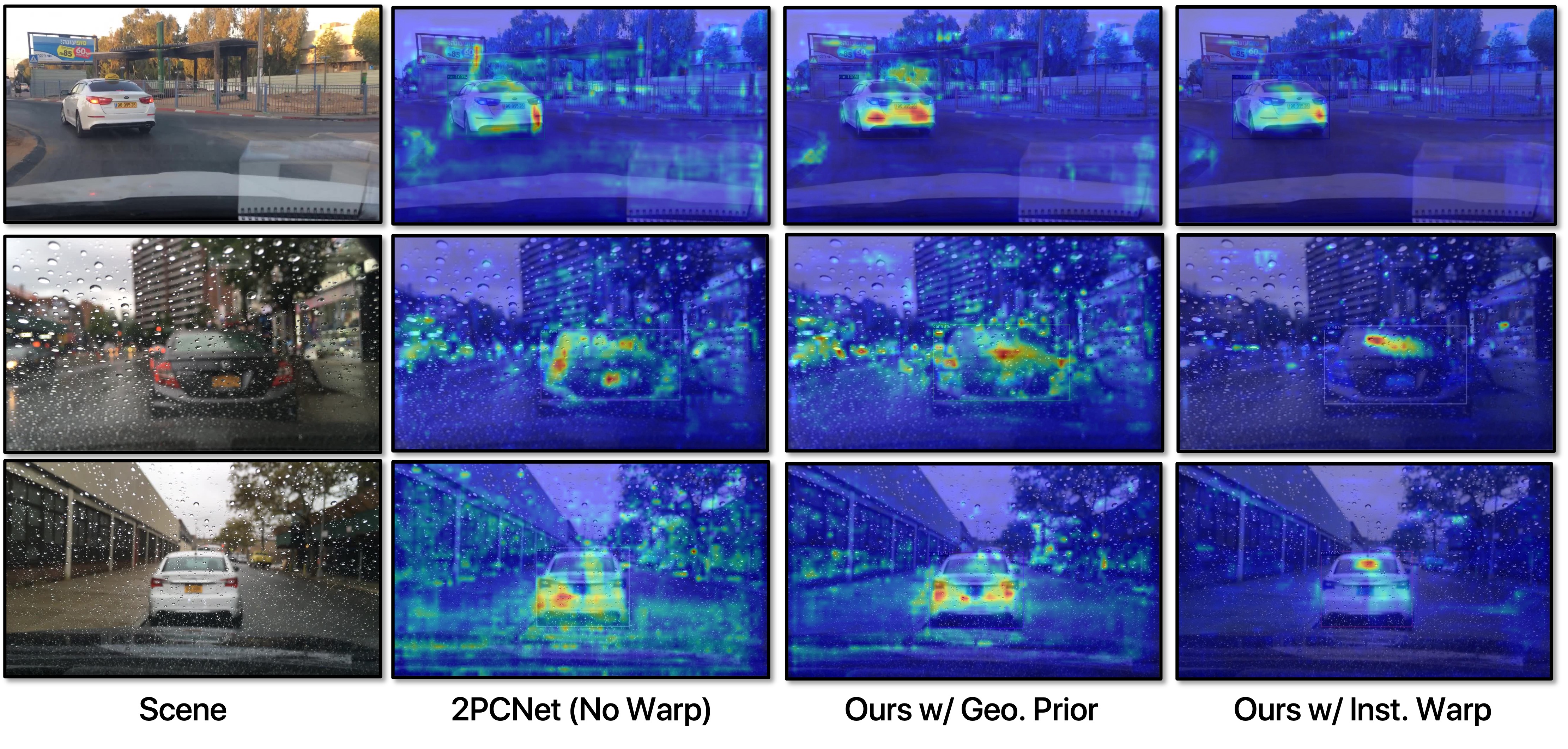
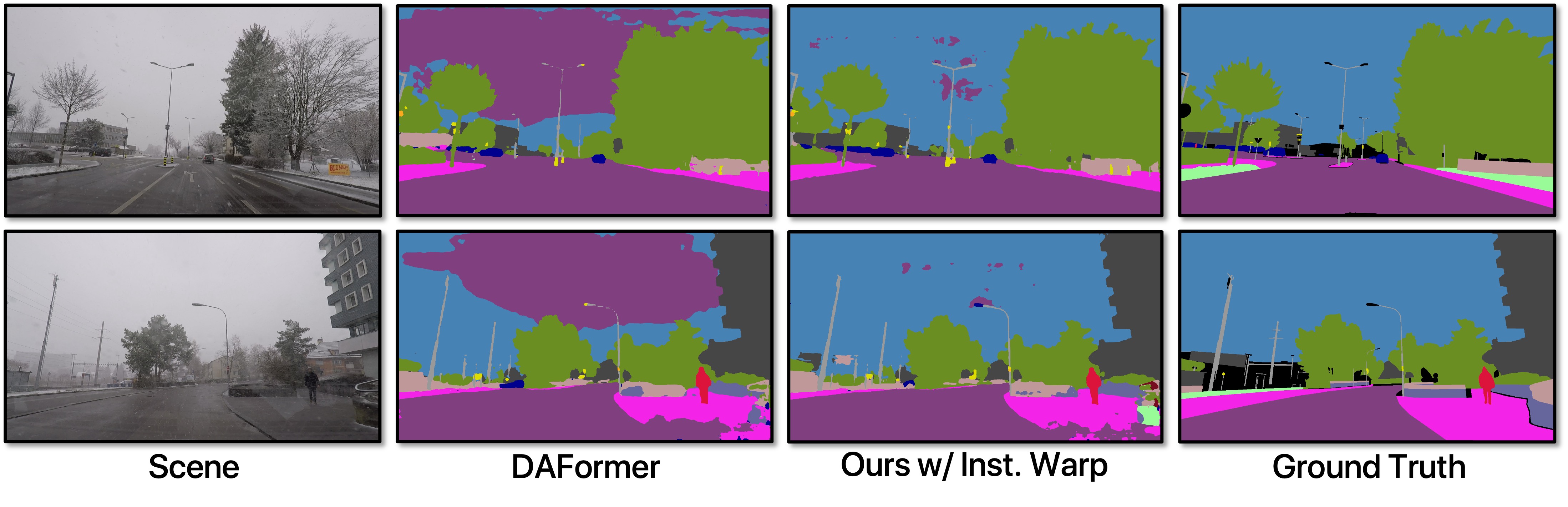
Why is Unsupervised Domain Adaptation Difficult?
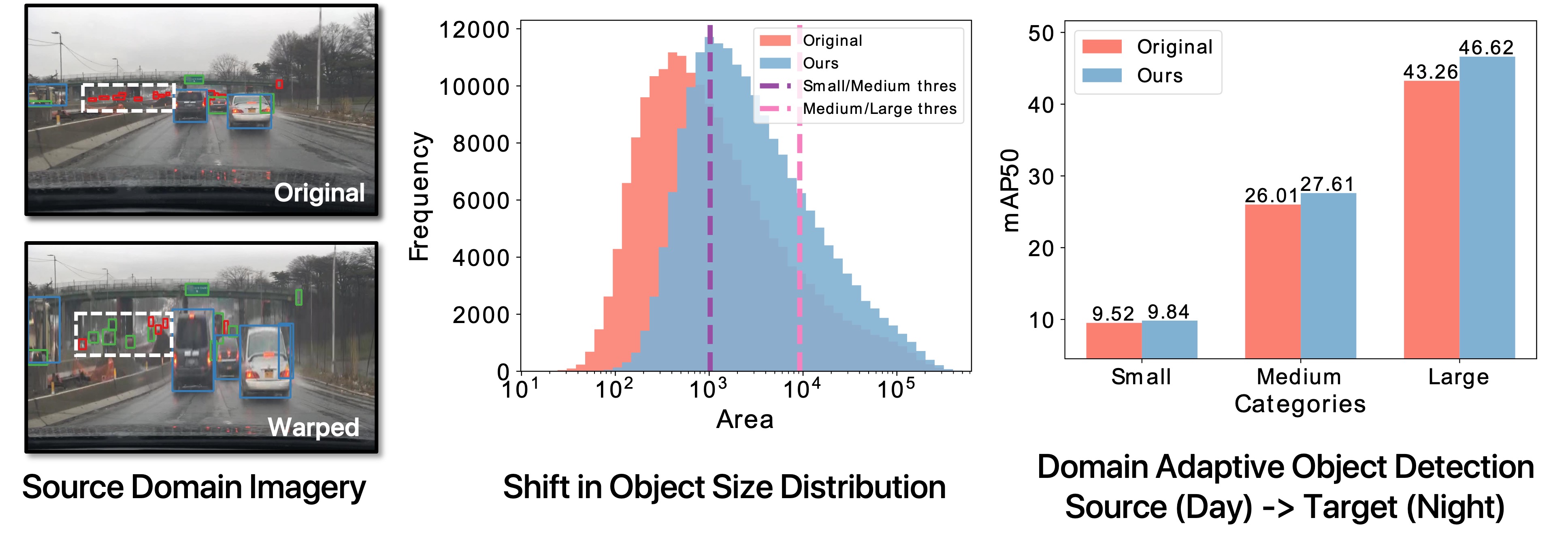
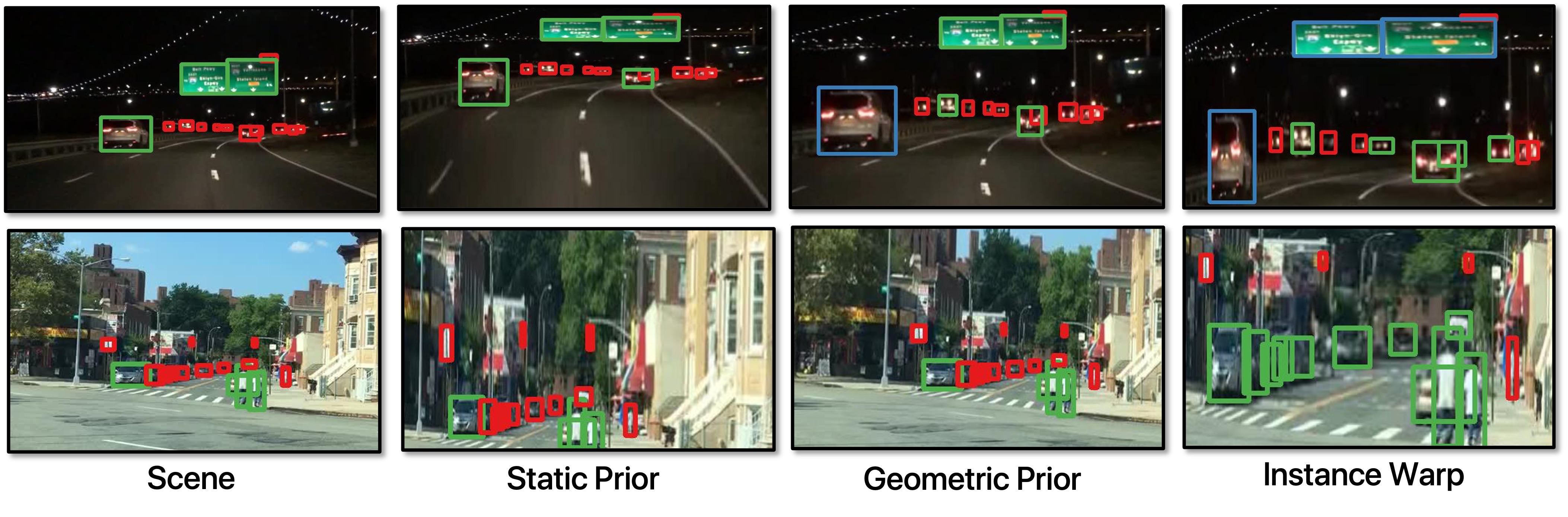
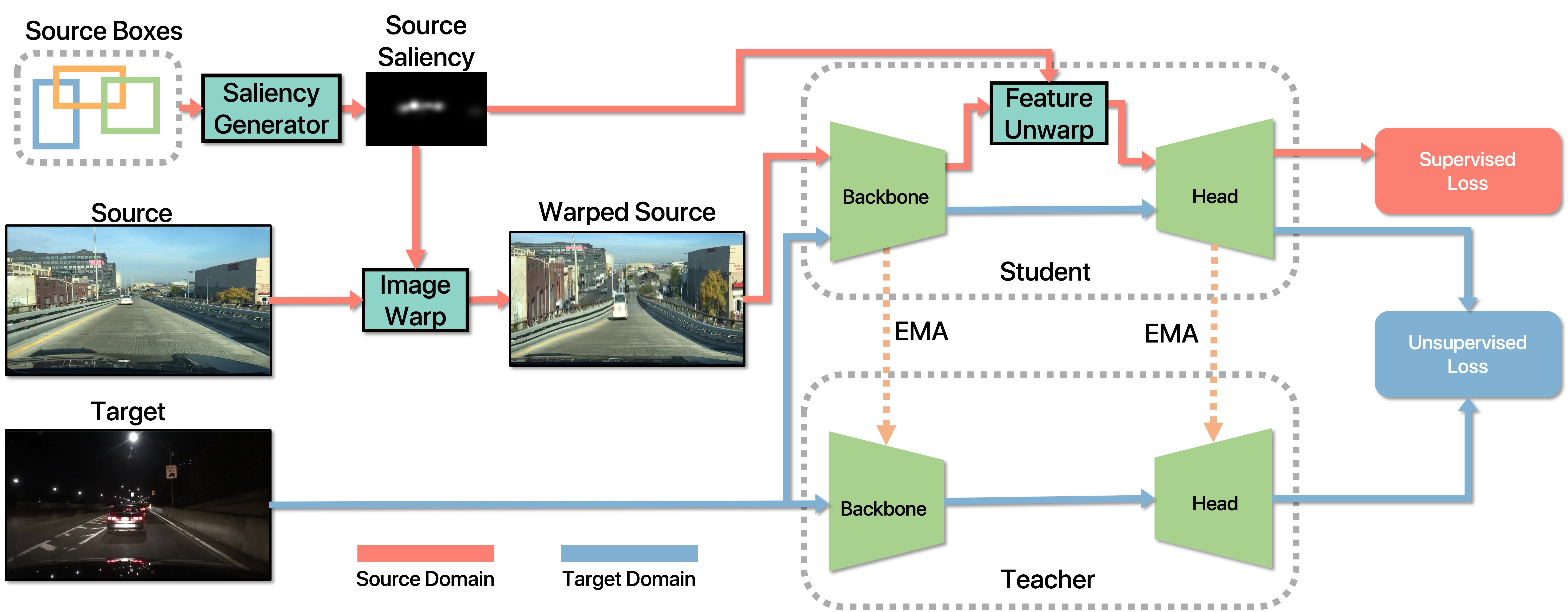
Unsupervised Domain Adaptation (UDA) is challenging because models are trained with dominant scene backgrounds that appear dramatically different across domains. Specifically:
- Object-Background Pixel Imbalance: Backgrounds occupy much more pixels than objects.
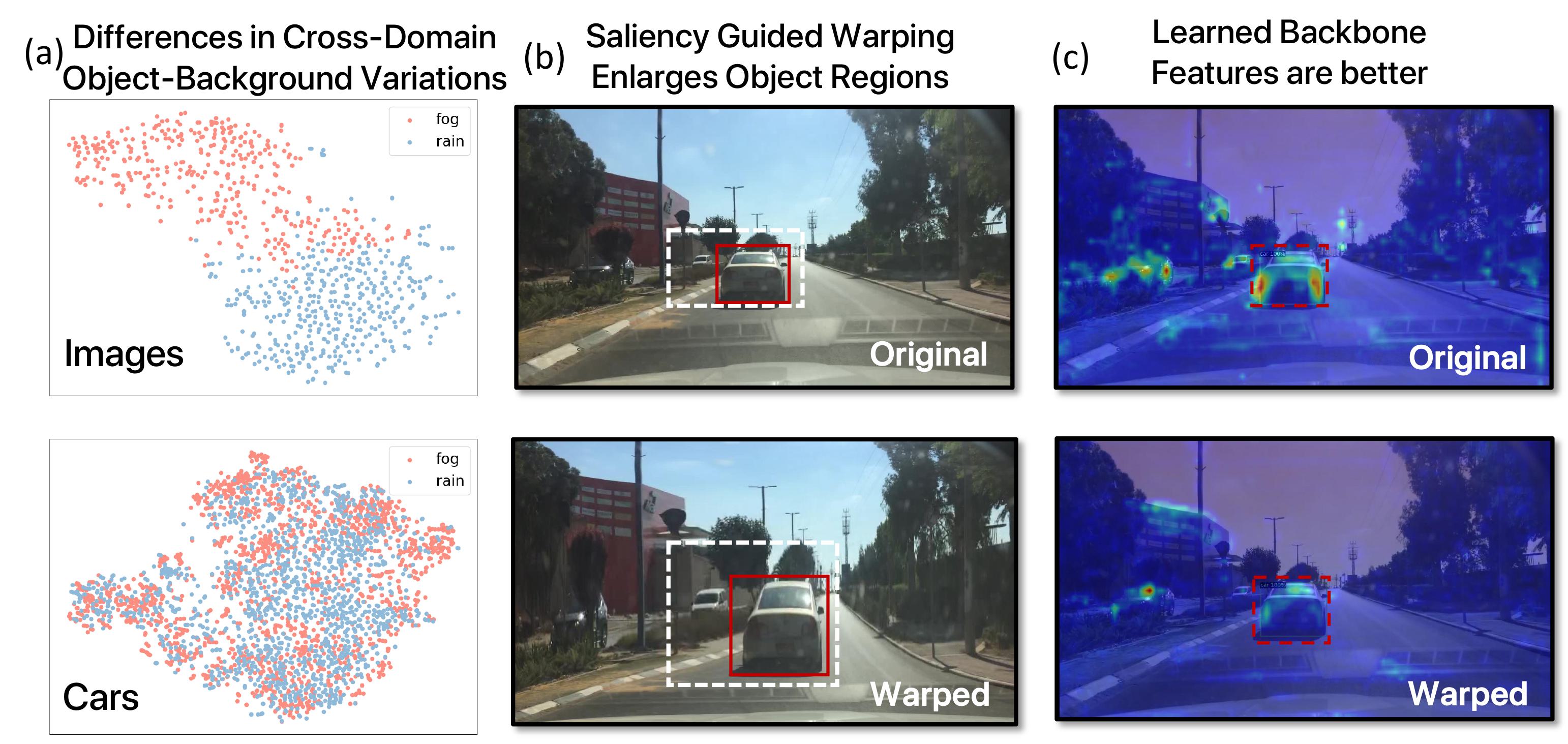
- Differences in Cross-Domain Object-Background Variations: Backgrounds exhibit significantly larger cross-domain variations than objects.